On the power of Open Source
A tale about Open Source, IBM, and XPM.
I often say: “Open Source is what brought me to IBM and Open Source is why I’m still at IBM today.” It’s true.
Open source at IBM
I’ve been fortunate enough to join a company that was one of the very first in the industry to understand the value of open source. Under the leadership of some brilliant executives, when others talked about open source as some communist endeavor to be frowned upon, IBM thought that if open source were to radically change the industry we would be better off being part of it than not. That’s how IBM went on to embrace open source. Of course, this didn’t happen overnight.
Wisely enough IBM executives tested out their belief starting with a few projects that looked promising enough and adopted progressively a stronger stance on open source as evidence that this was a winning proposition accumulated over time. Linux was one of those first projects along with Apache and Eclipse which came quickly after. These were followed by many others and over time doing open source became the norm.
When I joined IBM in the fall of 1999, that trend had already started and I fully benefited from it. I joined a small team in Cupertino to work on Xerces, the XML parser that IBM had contributed to the Apache Software Foundation (ASF). I spent my entire time working with the W3C community on developing specifications like XML and DOM and with the ASF community on developing Xerces. And on the weekend I got to go surfing! What was not to like? 😀
Since then I had the opportunity to work on many different open source projects such as Hyperledger and more recently OpenSSF.
XPM
Working on Xerces wasn’t my first experience in open source though. I actually started in open source before the term was even coined. Indeed, I made my first contribution to open source in 1990! I can’t really take full credit for this happening. As often in life this kind of stuff has at least as much to do with luck as anything else. I had just joined a small research team in France when one of my colleagues, Daniel Dardailler, told me that he and Colas Nahaboo had designed a simple format to store and display color icons on the X Window System for which he had quickly written a small piece of code to render them and that if I was interested it would be worth developing a more complete library for it.
I picked it up, rewrote the whole thing with a more robust parser and additional features, and distributed the first release of XPM2 on August 24th, 1990. Little did I know that I would end up maintaining this format and code for several years and that it would become a de facto standard for X. The last release I produced was on March 18th, 1998. (I still have all the code with the RCS archive and all!)
I now brag about it but I actually only started doing so a few years ago when I overheard someone talk about a person as “an open source dinosaur who started in open source in the early 2000s” That’s 10+ years later than when I started, I wonder what that makes me…
The power of Open Source
Besides the bragging rights I got from this what’s more important is that XPM is a good demonstration of the power of open source. Indeed, while I stopped maintaining the library others picked it up and it has been continuously maintained to this day. You can find it as part of the freedesktop gitlab repo.
Several releases have been produced to address security issues, memory leaks, as well as keeping the code to compile on newer systems. What better demonstration is there of the power of open source? It was still useful to someone else and because it was open source they could just pick it up and continue to maintain it. This obviously wouldn’t have been possible if it had been proprietary.
A wish
I wish vendors who stopped maintaining their software would release them in open source so that similarly to what happened with XPM others who still have an interest in the software could choose to maintain it if they want to. I have an old Garmin GPS marine unit with a proprietary memory card format for which one needs a proprietary reader to access the card from a PC via USB. The problem is that the only available driver for that card reader is for Windows 32bit!… I actually managed to use an old laptop that was collecting dust to access the card reader so I could update the firmware of my boat electronic devices but that’s absurd.
It’s ok with me that Garmin decides it’s not worth supporting my old hardware anymore but if they released the source code for the driver, users (a.k.a “the community”) could at least do it themselves and port it to newer systems. The frustration I get from this is probably not very different from what made Richard Stallman launch the Free Software movement when he couldn’t fix the buggy driver for his printer.
More on XPM
Speaking of printers… a couple of years ago, I noticed an entry “Open Source licenses” on my printer’s webpage. Always interested in open source I of course clicked on it to see what kind of software HP was using in that printer. Here is what appeared:
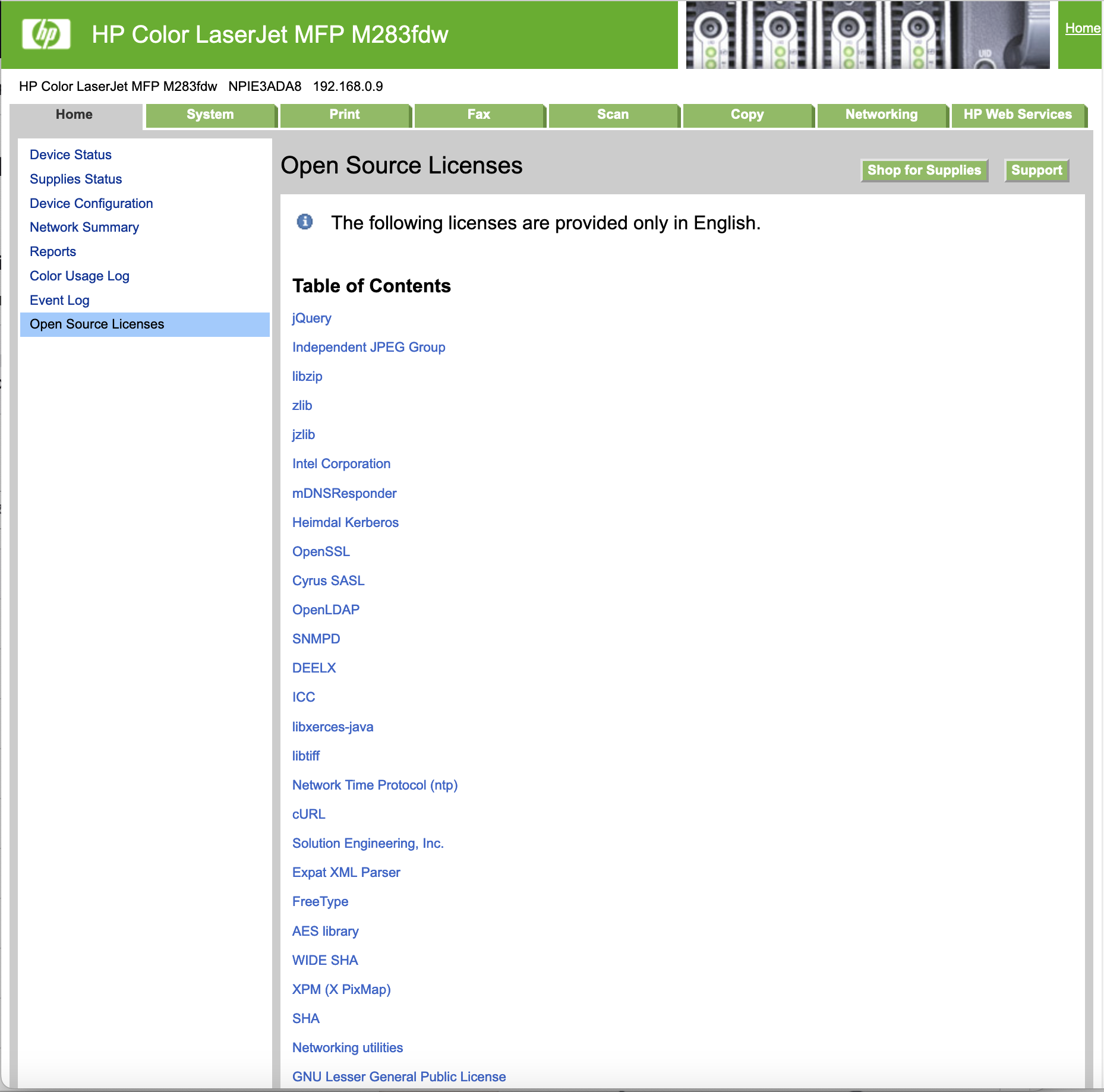
Do you see it? Close to the bottom. “XPM (X PixMap)”. Yup, that’s right. It turns out that my laser printer sitting a few feet away from my desk is using code I wrote some 30 years ago! How cool is that now? 😀
In case you wonder, it is probably used for the LCD screen which displays a bunch of icons:

Further reading
If you’re curious about XPM you can read more on the X PixMap wikipedia page.
There is also an interesting page on the story of Open Source @ IBM.
More on Linked Data and IBM
For those technically inclined, you can learn more about IBM’s interest in Linked Data as an application integration model and the kind of standard we’d like the W3C Linked Data Platform WG to develop by reading a paper I presented earlier this year at the WWW2012 Linked Data workshop titled: “Using read/write Linked Data for Application Integration — Towards a Linked Data Basic Profile”.
Here is the abstract:
Linked Data, as defined by Tim Berners-Lee’s 4 rules [1], has
enjoyed considerable well-publicized success as a technology for
publishing data in the World Wide Web [2]. The Rational group in
IBM has for several years been employing a read/write usage of
Linked Data as an architectural style for integrating a suite of
applications, and we have shipped commercial products using this
technology. We have found that this read/write usage of Linked
Data has helped us solve several perennial problems that we had
been unable to successfully solve with other application
integration architectural styles that we have explored in the past.
The applications we have integrated in IBM are primarily in the
domains of Application Lifecycle Management (ALM) and
Integration System Management (ISM), but we believe that our
experiences using read/write Linked Data to solve application
integration problems could be broadly relevant and applicable
within the IT industry.
This paper explains why Linked Data, which builds on the
existing World Wide Web infrastructure, presents some unique
characteristics, such as being distributed and scalable, that may
allow the industry to succeed where other application integration
approaches have failed. It discusses lessons we have learned along
the way and some of the challenges we have been facing in using
Linked Data to integrate enterprise applications.
Finally, we discuss several areas that could benefit from
additional standard work and discuss several commonly
applicable usage patterns along with proposals on how to address
them using the existing W3C standards in the form of a Linked
Data Basic Profile. This includes techniques applicable to clients
and servers that read and write linked data, a type of container
that allows new resources to be created using HTTP POST and
existing resources to be found using HTTP GET (analogous to
things like Atom Publishing Protocol (APP) [3]).
The full article can be found as a PDF file: Using read/write Linked Data for Application Integration — Towards a Linked Data Basic Profile
Linked Data
Several months ago I edited my “About” text on this blog to add that: “After several years focusing on strategic and policy issues related to open source and standards, including in the emerging markets, I am back to more technical work.”
One of the projects that I have been working on in this context is Linked Data.
It all started over a year ago when I learned from the IBM Rational team that Linked Data was the foundation of Open Services for Lifecycle Collaboration Lifecycle (OSLC) which Rational uses as their platform for application integration. The Rational team was very pleased with the direction they were on but reported challenges in using Linked Data. They were looking for help in addressing these.
Fundamentally, the crux of the challenges they faced came down to a lack of formal definition of Linked Data. There is plenty of documentation out there on Linked Data but not everyone has the same vision or definition. The W3C has a growing collection of standards related to the Semantic Web but not everyone agrees on how they should be used and combined, and which one applies to Linked Data.
The problem with how things stand isn’t so much that there isn’t a way to do something. The problem is rather that, more often than not, there are too many ways. This means users have to make choices all the time. This makes starting to use Linked Data difficult for beginners and it hinders interoperability because different users make different choices.
I organized a teleconference with the W3C Team in which we explained what IBM Rational was doing with Linked Data and the challenges they were facing. The W3C team was very receptive to what we had to say and offered to organize a workshop to discuss our issues and see who else would be interested.
The Linked Enterprise Data Patterns Workshop took place on December 6 and 7, 2011 and was well attended. After a day and a half of presentations and discussions the participants found themselves largely agreeing and unanimously concluded that: the W3C should create a Working Group to create a Recommendation that formally defines a “Linked Data Platform”.
The workshop was followed by a submission by IBM and others of the Linked Data Basic Profile and the launch by W3C of the Linked Data Platform (LDP) Working Group (WG) which I co-chair.
You can learn more about this effort and IBM’s position by reading the “IBM on the Linked Data Platform” interview the W3C posted on their website and reading the “IBM lends support for Linked Data standards through W3C group” article I published on the Rational blog.
On a personal level, I’ve known about the W3C Semantic Web activities since my days as a W3C Team Member but I had never had the opportunity to work in this space before so I’m very excited about this project. I’m also happy to be involved again with the W3C where I still count many friends. 🙂
I will try to post updates on this blog as the WG makes progress.
Open standards and globalization
Among the standards principles IBM announced on September 23rd, there is one that is particularly dear to me (surely because of my current responsibilities at IBM but also because of my background with W3C). This principle is what we refer to as the principle of “Global Application”. It reads:
Encourage emerging and developed economies to both adopt open global standards and to participate in the creation of those standards.
Despite what the OOXML proponents have been claiming for the sake of their own benefit, having multiple standards for the same task doesn’t do anybody any good. Multiple standards means market fragmentation and duplication of efforts. Market fragmentation and duplication of efforts mean less choice and higher cost.
As we move forward we must learn from the past while not letting it get in our way. We must ensure that standards are developed in such a way that all stakeholders can participate and feel compelled to do so. This is essential for all requirements to be addressed but also for everybody to have a sense of ownership. Both of these elements are key to the adoption of the standard by all.
I consider the case of the Uniform Office Format (UOF) a perfect example of our failure to do just that. What was it that led China to create its own format rather than work with us on expanding ODF so that it addresses their needs? Their work started with a fork from OpenOffice mind you. So, why weren’t they at the table with us?
We need to understand what went wrong and ensure that this doesn’t happen again. For everybody’s benefit. Failure to so will result in more pain for everybody, just like the pain we are experiencing with UOF.
The situation with UOF is now that China is trying to gain support from vendors like IBM. These vendors would like to play in the Chinese market but they have already heavily invested in ODF and are understandly not too keen on the idea of spending resources on UOF. They would rather see China adopt ODF. But ODF doesn’t quite fit China’s needs. So, efforts are being made towards a possible convergence of the formats but these are merely damage control that remain costly for all.
And this is not all. The Global Application principle cannot be separated from the principle of “Implementability” which reads:
Collaborate with standards bodies and developer communities to ensure that open software interoperability standards are freely available and implementable.
Indeed, one of the major barriers to global adoption by developing countries of the so called “international standards” is the toll on implementing them. Whether it is about paying just to access the document or about paying royalties to foreign companies for patents that read on the standard, the price tag this constitutes is just not acceptable to emerging countries. They already face enough challenges otherwise.
The European Commission as well as countries like India are trying to move the ball by developing policies that restrict public procurement to “open standards” which they define as being royalty free. This is provoking reactions from various organizations that want to stop this movement. Their main contention appears to be that we’ve been developing standards for decades on a RAND basis and adopting a royalty free only policy will rule out hundreds of existing standards and products. I say: tough!
It’s about time that we recognize that the way we’ve been doing standards isn’t going to work anymore. And we just cannot expect the world to be shackled by the way we’ve been doing things in the past.
Traditionally, IT standards have for the most part been developed by the western world and then pushed onto the rest of the world. A RAND based system might have been fine in an environment where the odds were balanced by the fact that all parties had more or less similar stakes in the game. But this doesn’t work when you add a bunch of new players who find themselves at the table empty handed.
So, it’s not surprise that the rest of the world is telling us “No, thanks”. Can we really blame them?
Those that cling onto the old ways are part of the past. The future simply cannot be based on a grossly unbalanced system that gives a hudge advantage to some parties. Getting rid of the toll on implementating standards is the price to pay to see them globally adopted. Failures to recognize that simple fact and attempts to derail the trends set by the European Commission and the likes are simply a waste of time.
Rave: IBM support
I don’t usually talk much about what IBM does but today I’m going to.
People I work with know that I’m usually pretty vocal about what I think the company doesn’t do well but if there is one thing that IBM does really well in my experience is support.
I’ve been at IBM for close to 9 years now and this has been true all along. Whenever some piece of material breaks down it gets fixed extremely quickly and painlessly.
I just had a couple of such experiences. Last week a disk on one of my computers started to fail. I called support in the afternoon and the very next morning a new disk was delivered to my door. I work from home.
Most defective items have to be returned. But IBM support makes that really easy. With the new item comes a label to ship the defective part back. All you have to do is place the old part in the package, stick the label on top of the old one, and order the pick up either by phone or over the web. In some cases, the box even contains a piece of tape for you to use. Can’t be easier.
Last Friday my son managed to pour a glass of water over my keyboard. I called support and this Monday morning I received a new keyboard.
In cases when the whole computer has to be sent, you first receive a shipping box – overnight – to send it in. Typically two days later you get it back repaired. The turnover can’t be better.
I should point out that this is no special services for employees. This is the exact same service anybody gets.
Anyway, I can’t say I have much experience with many other companies when it comes to support but I have never seen anything getting close to what IBM does in this regard.
I’ve actually realized that I like that so much that it’s often something I bring up when people ask me what it’s like to work at IBM.
So, it’s only fair that I should give the company credit for that. 🙂
Let’s be clear: The Apache Software Foundation does NOT support OOXML.
OK, I’ll admit that nobody has claimed otherwise. Yet.
But in these days and age you are never too prudent. It wouldn’t surprise me to see this or other similar fancy claim being published eventually.
Indeed, in its desperate and last minute attempts to convince National Bodies around the world that OOXML is happening anyway so they might as well support it as an ISO standard, Microsoft is eager to claim support by as many companies and organizations as possible.
As evidence, in its latest OOXML propaganda open letter Microsoft lists IBM among other companies as having “already adopted (or announced adoption of) Open XML in their products”. This, despite a clear explanation of the contrary by Rob Weir, published two months ago! Does anyone believe they haven’t seen it or heard about this? I sure don’t. And if there was any room for misunderstanding Bob Sutor’s statement filled that in.
A colleague in a foreign country even reported that in a National Body meeting he had been confronted by a representative from Microsoft who was trying to silence him via intimidation and insistence that IBM supported OOXML contrary to what he was saying.
Microsoft’s oversight of IBM’s denials is clearly not accidental. It is part of a well crafted and continuous disingenuous plan to convince NBs at all cost. There is already so much evidence of Microsoft going far beyond what most would consider normal lobbying behavior it is sickening. For one, I’m not ready to forget the case of the NGOs in India. Talk about dirty practices.
But what really is at the bottom of Microsoft’s claims is that basically any software that handles XML supports OOXML. While technically this is true to a certain degree, such a bold claim without any further qualification is pure misinformation. Obviously, one of the advantages of using XML is to make your format, whatever it is, easier to handle, it’s one of the fundamental benefits of using XML. But as I previously touched on in my entry on XML vs Open, there is a big difference between being able to handle XML files at the XML level and truly supporting the particular format at hand.
Supporting OOXML. cannot be merely declared on the sole basis that a software can read OOXML files, or store OOXML files. If that were the case, then any XML parser could be said to support OOXML and the Apache Software Foundation could be said to support OOXML because its XML parser, Xerces, can read OOXML files (one would actually have to unzip them first but it’s not like Microsoft would stop at that kind of detail). But it takes much more than that to really support OOXML.
One has to understand the actual structure beyond the XML representation and the semantic associated to each and every piece of data found in an OOXML file. That’s what the 6000+ pages of the specification are supposed to define, unfortunately they do that extremely poorly.
The good news is that I don’t think Microsoft is fooling that many people. Based on my own observation of Microsoft representatives and the way they talk to people they seem to be completely oblivious to the fact that they appear as if they think the people they are talking to are too stupid to see through their tired arguments. I’ve got news for them: people aren’t that stupid. Thankfully. And I’m hopeful the results at the end of the month will make that clear.
The other good news is that whether OOXML gets approved or not, I believe Microsoft will pay a high price for all of its mischief and its image will come out of this badly damaged, something they can only blame themselves for.
In the meanwhile, don’t take for granted any claims of support for OOXML from Microsoft. The fact that Microsoft claims IBM has adopted OOXML can only make one wonder about all the other companies they list…
About

Arnaud Le Hors 2024 – CC BY 4.0
After several years focusing on strategic and policy issues related to open source and standards, including in the emerging markets, I decided to get back to my roots and focus more on technical work. I am involved in several software standards and open source development efforts with IBM. I am currently the main representative for IBM at W3C and INCITS, and serve as the Vice Chair of the OpenSSF Technical Advisory Committee.
I am a Senior Technical Staff Member part of the Open Technologies group at IBM. I have been working on standards and open source for over 30 years, both as a staff member of the X Consortium and W3C, and as a representative for IBM. I have been involved in every aspect of the open technology development process: technical, strategic, political, and legal. I was editor of several key web specifications including HTML and DOM and was a pioneer of open source with the release of libXpm in 1990 (which is still in use today! 😊). I participated in several prominent open source projects including the X Window System and the Apache XML parser Xerces, and more recently the blockchain framework Hyperledger Fabric. I’ve chaired several technical groups at W3C and OASIS, such as the XML and Linked Data Working groups, as well as more recently the Hyperledger Technical Advisory Committee and the LF Edge Open Retail Reference Architecture group.
